AWS Multi-Region Database
Overview
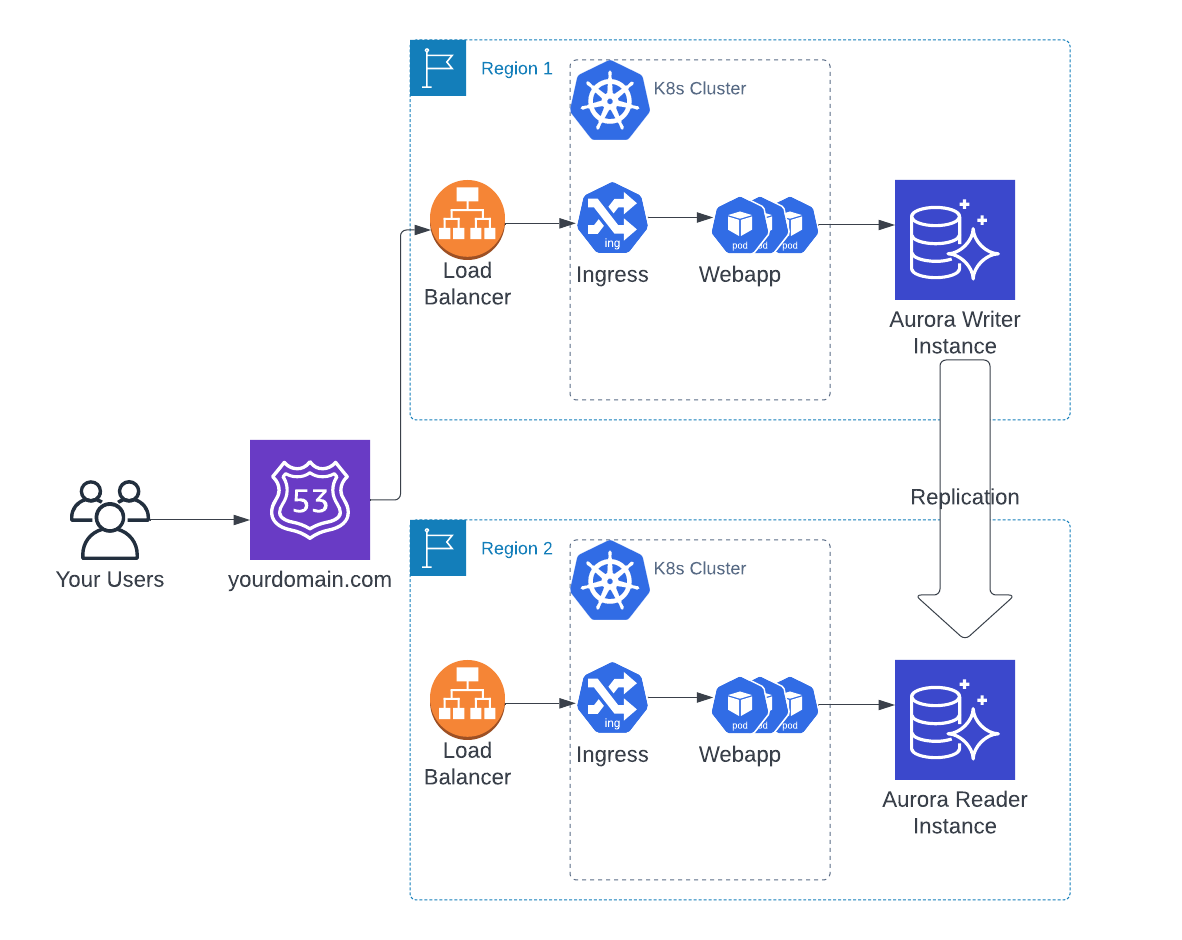
A common use case for multi-region architectures is for “read-only” regions. That is, an app’s customer base may be divided geographically by a large distance such that it is impossible to find a single location to place your servers such that there is no noticeable lag in the connectivity to the back-end. The common solution is to put the “primary/write” database+servers in one location (typically close to the main cluster of users), and separate “secondary/read” replica database+servers in another close to other clusters of users.
For instance, if a webapp has an active community in both the US and India, it would be wise to implement such an architecture, to dramatically cut latency and increase user experience.
This task traditionally is a massive headache to implement, but thanks to Opta, there is a pretty straightforward path to execute and achieve all the desired features using Postgres and AWS as our cloud provider. The steps to achieve this goes as follows:
- Create + apply an Opta environment yaml for the writer region
- Create + apply your Opta yaml for your app, including the database and with an Aurora Global enabled
- Create + apply an Opta environment yaml for the secondary, reader region
- Create + apply your Opta yaml for your app in the secondary region, with the db set to be a read replica in the Global Cluster created
- (Optionally) Enable VPC Peering
Create + apply an Opta environment yaml for the writer region
For this there’s nothing special and just use a typical Opta environment yaml:
name: staging-region-1
org_name: my-org
providers:
aws:
region: XXXX # Your primary region
account_id: YYYY # Your 12 digit AWS account id
modules:
- type: base
- type: k8s-cluster
- type: k8s-base
# Feel free to add extra modules (like DNS) as needed
Fill in and save to a new file, and run opta apply when ready.
Create + apply your Opta yaml for your app, including the database and with an Aurora Global enabled
This will vary a lot depending on the needs of your application, but using the getting started example app, it should looks as follows:
# hello.yaml
name: hello
environments:
- name: staging
path: "opta.yaml" # the file we created in previous step
modules:
- name: db
type: postgres
instance_class: "db.r5.large"
create_global_database: true
- type: k8s-service
name: hello
port:
http: 80
# from https://github.com/run-x/hello-opta
image: ghcr.io/run-x/hello-opta/hello-opta:main
healthcheck_path: "/"
# path on the load balancer to access this service
public_uri: "/hello"
links:
- db
You may note that the database module specifies 2 important fields:
instance_class: "db.r5.large"– Aurora Global databases demand large minimum sizes, starting only atdb.r5.large(ordb.r6g.largefor the r6g series)create_global_database: true– The Aurora Global database is created as an add-on shell to the standard Opta postgres database, and needs to be explicitly enabled.
Fill in and save to a new file, and run opta apply when ready. After the apply you should see an output named
global_database_id – make a note of this and continue
Create + apply an Opta environment yaml for the secondary, reader region
For your secondary region, the environment yaml would be pretty similar, except that, foreseeing the possible need to do VPC
peering, we can not use the default CIDR block for your VPC, and must put in a new one to make sure that there is no
IP conflicts between the 2 regions. Opta’s default CIDR block is 10.0.0.0/16 and to keep things simple the example below
is just switched to 10.1.0.0/16.
name: staging-region-2
org_name: my-org
providers:
aws:
region: XXXX # Your secondary region
account_id: YYYY # Your 12 digit AWS account id
modules:
- type: base
total_ipv4_cidr_block: "10.1.0.0/16"
private_ipv4_cidr_blocks: [
"10.1.128.0/21",
"10.1.136.0/21",
"10.1.144.0/21"
]
public_ipv4_cidr_blocks: [
"10.1.0.0/21",
"10.1.8.0/21",
"10.1.16.0/21"
]
- type: k8s-cluster
- type: k8s-base
Fill in and save to a new file, and run opta apply when ready.
Create + apply your Opta yaml for your app in the secondary region, with the db set to be a read replica in the Global Cluster created
Now to create the secondary/read application, it’s nigh identical to the first instance, except that this time
we do not have create_global_database set, but instead have the field existing_global_database_id set to the global
database id we’ve been keepign track of previously.
# hello.yaml
name: hello
environments:
- name: staging
path: "opta2.yaml" # the file we created in previous step
modules:
- name: db
type: postgres
instance_class: "db.r5.large"
existing_global_database_id: "XXXX" # The global database id we were keeping track of
- type: k8s-service
name: hello
port:
http: 80
# from https://github.com/run-x/hello-opta
image: ghcr.io/run-x/hello-opta/hello-opta:main
healthcheck_path: "/"
# path on the load balancer to access this service
public_uri: "/hello"
links:
- db
Fill in and save to a new file, and run opta apply when ready. You will note that the database name, username, and
password environment variables are not set– that’s because the reader instance does not manage them and they must be
taken from the service linked to the writer/master database (the database host is new and valid because we’ll be directing
the database connection to the endpoint of the reader instance just created). Go ahead and use opta shell on the first service yaml to
figure that out, and afterwards use opta secret update to add them to this service as secrets.
And that’s it! You know have your application running on two regions, with one region handling reads and the other only writes!
Enable VPC Peering
Naturally, one may wish to also be able to write from the application servers in the second region, sending the connection the long distance/latency to the primary region. Depending on how your application code handles multi-region, this can be required or not. Thanks to our foresight in choosing non-overlapping VPC CIDR blocks (10.0.0.0/16 and 10.1.0.0/16), this should be no problem. Just follow our VPC peering guide found here, and you should be good to go (just make sure to create a new secret to securely pass the writer db host to the secondary regions' containers).
Caveats
Handling Routing
One subject up for debate is how routing will be done to the secondary region. This matter has potentially dozens of possible implementations (e.g. it can be done at the frontend were the frontend knows its location and which loadblancer to send traffic to, or the location is saved as part of login/a first http request and used by the frontend to route, or the app uses geo-routing capabilities of its cloud provider etc…) which Opta will work to explore in the future. For now, pretty much all options are available to the user to add outside of Opta as they please, as one of the beauties of Opta is that all the architecture is in your account, owned by you, and you are totally free to add further resources.
Handling Deployment
Due to the fact that there are now “2” services for “2” environments, deployments now will be a little more complex– instead of running opta apply/deploy once you will need to do it twice, once for each region. This means that the regions will not be always in sync as to the version of code they’re running, and cannot be fully applied atomically (e.g. the deployment could succeed in one region and fail in another). If one however keeps good stewardship of the CI/CD pipelines and uses the database best practices outlined in our migration guide then this shouldn’t be a problem.
Conclusion
And that’s how you can quickly and easily achieve multi-region webapps with postgres databases! While there’s still some complexity and added maintenance, we hope Opta continues to delivery on its user experience quality guarantees. Multi-region architecture is an ongoing initiative within the Opta project, so please stay tune, and drop by our community slack for questions or feature requests.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.